Rilasciata in produzione applicazione Wasteful basata su Flutter
11 Marzo 2022
Il dbms Cassandra ha tra le sue principali caratteristiche, quella di essere un database replicato e distribuito. La replica e la distribuzione dei dati gestiti dal Cassandra si basa sull’unità minima infrastrutturale definita nodo (di norma equivalente a un host) sui quali vengono persistiti i dati. I nodi che trattano gli stessi dati, aggregati logicamente tra di loro e in vari livelli, fanno parte di un cluster.

I dati vengono appunto distribuiti all’interno dei nodi di un cluster, e ciascun nodo replicato sugli altri secondo le logiche di replica definite (min 1, max n. nodi).
Gli strumenti nativi del Cassandra forniscono esclusivamente una gestione dei backup dei dati a livello di nodo.
È facile dedurre che il backup di un singolo nodo non rappresenta in linea di massima un backup consistente dei dati di un intero cluster. Per questo motivo, una politica di backup universalmente valida a prescindere dalla configurazione specifica di un cluster dovrà prevedere i backup di tutti i nodi dello stesso.
Di base gli strumenti che il Cassandra stesso offre per la gestione dei backup dei dati sono 2:
Snapshot di un nodo
Backup incrementali
Le snapshots vengono effettuate tramite l’utility nodetool, il quale permette di eseguire un backup completo dello stato attuale di un nodo, o di effettuare un backup con maggiore granularità (keyspace, table). La snapshot forza il nodo sul quale viene effettuata a svuotare le scritture presenti nella memtable e persisterle sul file system nelle relative SSTable (.db non modificabili). Successivamente viene creato un hard link di ogni *SSTable inclusa nel backup nella cartella snapshots di ciascuna tabella.
In quanto hard link e non copie dei file, una snapshot occupa pochissimo spazio aggiuntivo sul disco. Tuttavia lasciare le snapshot sul file system causa un notevole incremento nell’utilizzo dello spazio disco perchè impedisce l’eliminazione dei vecchi file eseguita a seguito del processo di compattazione (merge delle varie SSTable della stessa tabella in un unico file). Per questo motivo un approccio possibile potrebbe essere quello di copiare le snapshot su uno storage esterno, ed eliminare le snapshot dal filesystem del nodo.
Per quanto detto nelle considerazioni generali, per avere un backup consistente dell’intero cluster, l’utilizzo delle snapshots dovrebbe essere concertato tra i vari nodi del cluster, e avviato in contemporanea tramite l’utilizzo di strumenti che permettano il parallelismo dei comandi (pssh, ansible etc…).
Lo stesso vale per i restore: Per poter effettuare il rollback dello stato del cluster ad un dato momento è necessario effettuare il restore su ogni nodo, altrimenti i nodi che non vengono ripristinati aggiornerebbero i nodi ripristinati con i dati più nuovi.
Punti critici delle snapshots:
Forzare il flush della memoria sul disco, impatta negativamente sulle prestazioni generali del cluster; per questo motivo è sconsigliato effettuare spesso delle snapshots.
Effettuando un backup completo di tutte le SSTable è possibile, dato il meccanismo di compattazione, che gli stessi dati siano presenti in più file inclusi nella snapshot, aumentando lo spazio occupato.
Rendono necessaria una gestione scrupolosa di rimozione delle vecchie snapshot per non impattare negativamente sullo spazio disco occupato.
A differenza delle snapshot effettuate tramite nodetool i backup incrementali sono una funzionalità da poter abilitare a livello di nodo. Una volta abilitata, il Cassandra crea degli hard link per ogni nuova SSTable creata a seguito di un flush della memtable dall’ultima snapshot effettuata. Non vengono creati hard link delle SSTable create a seguito della compattazione, in quando tutti i dati sono già presenti nelle varie SSTable create. Utilizzando lo stesso meccanismo degli hard link delle snapshot, anche mantenere a lungo i backup incrementali sul filesystem del nodo impedisce l’eliminazione delle vecchie SSTable causando una crescita notevole dello spazio occupato.
A differenza delle snapshot però, limitandosi alla creazione di hard link, questo meccanismo non inficia sulle prestazioni del cluster. L’utilizzo dei backup incrementali per il ripristino inoltre garantisce un’ottima granularità sul momento del ripristino desiderato (utilizzando tutti i file delle SSTable fino ad un determinato istante). Per limitare il problema dell’occupazione del disco, similmente a quanto ipotizzato per le snapshot, è possibile copiare i file dei backup incrementali su uno storage separato dal nodo, e svuotare la cartella contenente gli hard links.
Punti critici dei backup incrementali:
Se usati da soli, è necessario conservare tutte le SSTable nei backup, senza possibilità di buttar via le più vecchie.
Il backup è rappresentato da una molteplicità di piccoli file, non semplici da gestire.
Si conservano nei backup anche i dati che vengono eliminati (sono contenuti nei vecchi SSTable), dunque i backup occupano molto più spazio degli effettivi dati presenti nel cluster.
Essendo 2 meccanismi tra loro indipendenti e con granularità diverse è possibile sfruttare i vantaggi di entrambi con l’obiettivo di limitare lo spazio occupato dai backup, mantenendo una buona granularità per il point-in-time restore (legata alla configurazione del flush della memtable). L’idea di fondo è quella di sfruttare le snapshot come backup di base, effettuandole con cadenza predefinita (1 volta al giorno quando il cluster è scarico sarebbe un buon approccio), e sfruttare invece i backup incrementali per avere il point-in-time tra le snapshot.
In questo modo si eviterebbe di sovraccaricare l’I/O dei nodi con le snapshot e di dover mantenere tutta la storia dei backup incrementali, conservando esclusivamente quelli tra le snapshot che verranno mantenute.
Ovviamente bisognerà ugualmente far attenzione alla gestione dello spazio disco dei filesystem dei nodi:
Svuotando la cartella dei backup incrementali dopo ogni snapshot
Rimuovendo le snapshot dopo averle copiate su un altro storage.
Il processo di copia dei file dei backup incrementali su storage esterni potrà essere effettuato con la periodicità desiderata, tenendo presente però che un eventuale fallimento del nodo comporterà la perdita dei dati dall’ultima sincronizzazione effettuata.
Il restore dei dati ad un determinato momento comporterà l’utilizzo dell’ultima snapshot catturata prima dell’istante desiderato più le SSTable dei backup incrementali fino ad esso (solo quelle più recenti della snapshot utilizzata).
I commit log sono dei file che contengono tutte le transazioni effettuate sul nodo del cluster. Qualsiasi operazione, prima di essere effettuata nella memtable del nodo viene persistita su filesystem, in modo da avere lo storico delle transazioni da utilizzare come fault tolerance. Quando un nodo smette di funzionare, al suo riavvio la memtable viene riempita con tutte le transazioni presenti nei commit log.
Analogamente ai backup incrementali, è possibile sfruttare i commit log archiviandoli, per ottenere un point-in-time recovery molto preciso, affiancandone l’utilizzo alle snapshots.
Dunque in caso di necessità di recovery si utilizzerebbe la snapshot più recente antecedente al momento desiderato e tutti i commit log contenenti le transazioni successive alla snapshot. A differenza dei meccanismi precedentemente descritti i commit log non interferiscono con la normale compattazione delle SSTable del Cassandra.
Pro:
Point-in-time molto preciso con granularità al millisecondo grazie al replay di tutte le transazioni fino al momento desiderato.
Nessuna interferenza con l’eliminazione delle vecchie SSTable
Contro:
La gestione dello spazio disco occupato dai commit log va gestita accuratamente.
Il replay dei commit log richiede il riavvio del nodo. Questa è un’operazione onerosa dal punto di vista dell’utilizzo di risorse, che potrebbe comportare un downtime causato dal ripristino, superiore agli altri approcci.
Ovviamente c’è la possibilità di combinare tutte e 3 i tipi di backup in modo da avere un point-in-time recovery molto preciso e tamponare parzialmente i contro di ciascuno. Questo implica una gestione accurata dello spazio disco del nodo, e un processo di recovery più complesso, che si dovrà avvalere di tutti e 3 i layers.
I Software di terze parti per la gestione dei backup del cluster cassandra sono pochi, e generalmente con limitate funzionalità (Es. tablesnap).
È tuttavia attualmente presente un progetto, rilasciato con licenza open-source, che fornisce alcune funzionalità che possono agevolare notevolmente la gestione dei backup di un Cluster Cassandra;
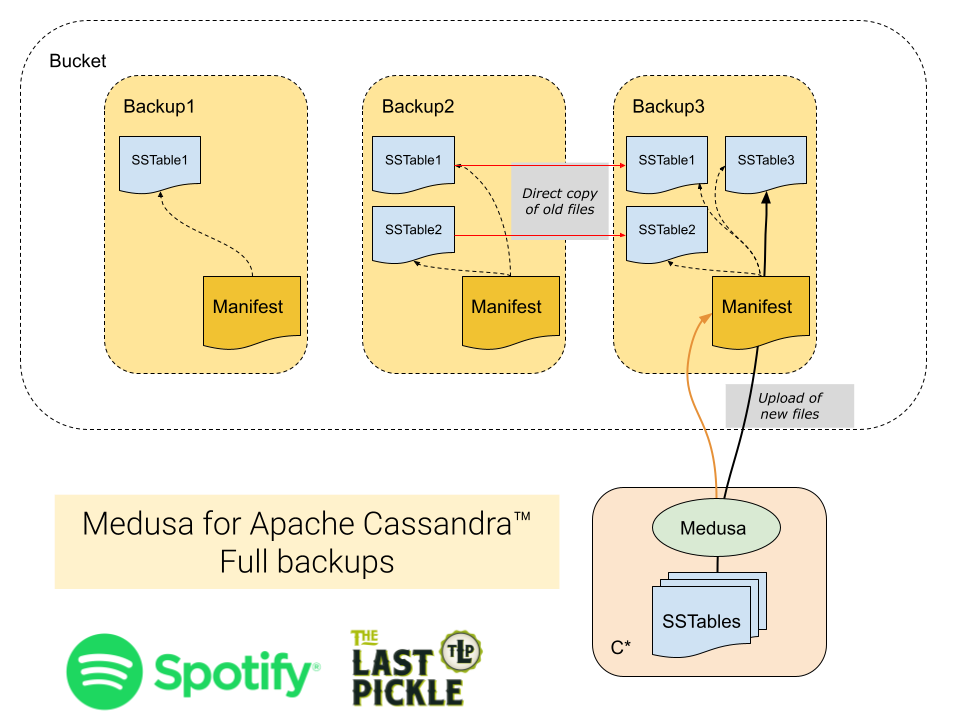
Si tratta del progetto Medusa, il cui codice è stato rilasciato da Spotify in collaborazione con The Last Pickle. Il tool scritto in python e utilizzabile a riga di comando, implementa le seguenti funzionalità:
Backup di un singolo nodo.
Ripristino di un singolo nodo.
Ripristino di un intero cluster.
Ripristino selettivo di singoli keyspaces e tabelle.
Supporto di cluster con singolo token e vnodes.
Eliminazione semplificata dei vecchi backups.
Modalità di backup completa o incrementale.
Verifica automatica dei dati ripristinati.
Inoltre questa soluzione ha compatibilità con tutte le versioni di Cassandra successive alla v2.1.0, e grazie alla libreria link:http://libcloud.apache.org/(Apache libcloud) sulla quale si basa supporta l’utilizzo di diverse soluzioni di storage quali:
AWS S3
Google Cloud Platform GCS.
Local Storage
I vari providers supportati dalla libreria.
Uno degli scopi del sistema di backup è quello di effettuare il restore di una precedente copia dei dati a causa di un errore utente/software, cancellazione accidentale, oppure di un evento catastrofico.
L’utilizzo di una soluzione di monitoraggio del cluster Cassandra permettere di diminuire il tempo medio necessario per individuare una problematica di sistema del Cassandra e di poter intervenire il prima possibile con le procedure di backup/restore.
Esistono già soluzioni open-source basate su Prometheus per effettuare il monitoring e l’alerting dello stato del cluster Cassandra. In particolare esistono soluzioni open-source come il Cassandra Exporter che permette di monitorare oltre allo stato ed alle performance dei singoli nodi anche molte metriche specifiche tra cui quelle relative ai CommitLog, Storage, SSTable, Keyspace, ThreadPool, Cache, Streaming operation (repair, bootstrap, rebuild), Compaction, etc.
L’utilizzo di un sistema di monitoraggio basato su Prometheus potrebbe essere esteso al monitoraggio sullo stato dei backup del cluster. A questo riguardo sarebbe sufficiente lo sviluppo di un piccolo exporter Prometheus specifico che verifichi lo stato dei backup con informazioni relative allo spazio disco usato o quello disponibile per lo storage dei backup, lo stato degli ultimi backup ed i dati trasferiti per ogni nodo, etc.
Le metriche potrebbero essere mostrate in apposite Dashboard Grafana per permetterne una efficace consultazione ed inoltre potrebbero essere creati alert opportuni per segnalare eventuali problematiche relative ai backup.
Viste le varie possibilità, la soluzione ottimale per il sistema di backup di un cluster Cassandra è fortemente dipendente dai requisiti in termini di granularità (per i ripristini point-in-time) e di storage che si andranno a utilizzare per l’allocazione dei backup stessi.
Dato che l’implementazione e test di script e strumenti per l’orchestrazione della soluzione è sicuramente un compito non banale e soggetto a possibili errori, il consiglio è quello di partire dalla base esistente (vedi Software di terze parti) e integrarla ove necessario con soluzioni ad-hoc che siano capaci di sfruttare i meccanismi discussi in precedenza.
Inoltre, a prescindere dal tipo di soluzione che si andrà ad adottare, l’utilizzo di strumenti di monitoring ai vari livelli faciliterà la verifica e il mantenimento della stessa anche in condizioni critiche. La verifica dello stato dei backup infine con un monitoraggio specifico (alerting, aggregazione dati) generalmente non incluso negli strumenti di backup, potrebbe completare la soluzione di backup prevista.
[Cassandra-Medusa] https://github.com/spotify/cassandra-medusa
[Apache_libcloud] http://libcloud.apache.org/
[Libcloud_supported_Providers] https://libcloud.readthedocs.io/en/latest/supported_providers.html#object-storage
[Prometheus] https://prometheus.io/
[Cassandra_Exporter] https://github.com/criteo/cassandra_exporter
[Grafana] https://grafana.com/
Business Software Solutions