Released in production our flutter based app 'Wasteful'
11 March 2022
[Prometheus] è un sistema open-source di monitoring e di strumenti di alerting originariamente sviluppato da [SoundCloud]. Il sistema è nato nel 2012 ed è stato progressivamente adottato da molte aziende ed organizzazioni ed ha una comunità molto attiva di utenti e sviluppatori che lo supportano.
Adesso [Prometheus] è un sistema open-source indipendente da qualunque società e per enfatizzare questa sua natura nel 2016 Prometheus è entrato a far parte della [CCNF] come secondo progetto ufficiale dopo il [Kubernetes].
Le caratteristiche principali di Prometheus sono:
un multi-dimensional data model con dati delle time series identificati dal nome della metrica e da coppie chiave/valore
PromQL, un linguaggio di query flessibile ideato per interrogare facilmente il data model multidimensionale
nessuna dipendenza da uno storage distribuito; ogni singolo nodo server è autonomo
collezionamento delle time series attraverso un modello di tipo pull tramite HTTP
pushing delle time series supportato tramite un gateway intermediario
target identificati tramite un service discovery o una configurazione statica
supporto a molte modalità di graficazione e dashboarding dei dati presenti
Prometheus effettua lo scrape dai job opportunamenti instrumentati sia direttamente che tramite un intermediario push gataway per gli short-lived job. Prometheus effettua localmente il salvataggio di tutte le metriche di cui ha fatto scrape ed esegue le regole definite al suo interno sia per aggregare i dati e generare nuove time series dai dati esistenti, sia per generare gli eventuali allarmi. Grafana o altri API consumer possono essere utilizzati per visulizzare i dati collezionati.
La maggior parte di Prometheus è scritto in Go rendendo così semplice fare la build ed il deploy di binari precompilati e statici.
Prometheus è indicato per salvare ogni tipo di time series puramente numeriche ed è stato pensato sia per un monitoraggio machine-centric che per un monitoraggio di un’architettura service-oriented altamente dinamica. In un mondo a microservizi il supporto per collezioni di dati multi-dimensional è uno dei sui punto di forza.
Prometheus è stato progettato per essere affidabile e per essere il sistema da consultare per diagnosticare velocemente quando ci sono dei problemi. Ogni Prometheus server è standalone, non è dipendente dallo storage di rete o da altri servizi remoti in modo da poter facilmente capire quale parte della tua infrastruttura ha dei problemi senza la necessità di effettuare un setup estensivo per essere utilizzato.
La figura successiva illustra l’architettura generale della soluzione Prometheus.
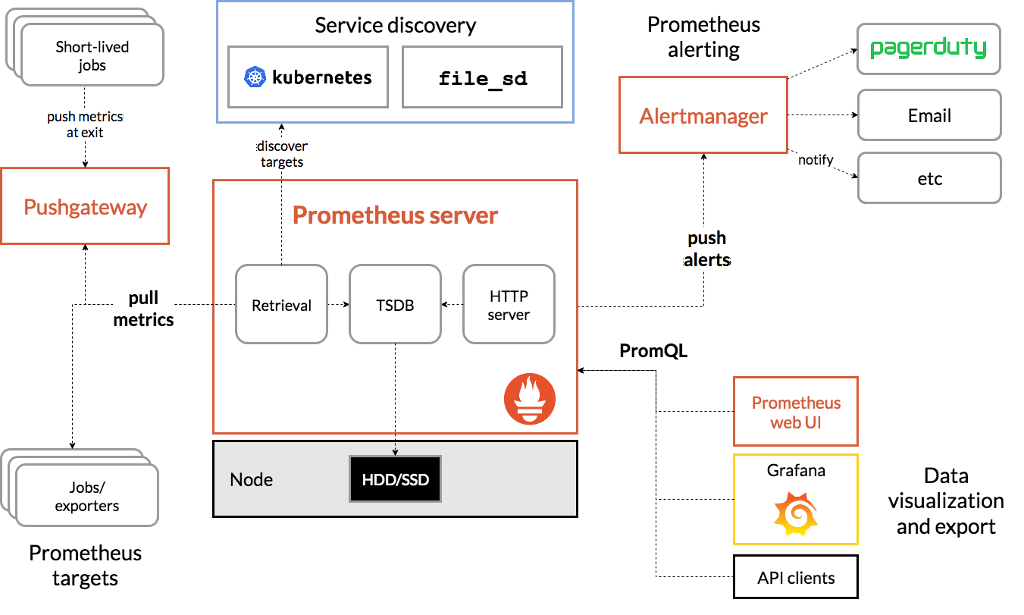
Prometheus archivia tutti i dati come time series: un flusso di valori “temporalizzati” (con un timestamp) appartenenti alla solita metrica ed allo stesso insieme di etichette (label).
Ogni time series è univocamente identificata dal suo nome e dall’insieme di coppie chiavi-valori anche conosciute come etichette (label).
Per esempio una time series con una metrica con nome api_http_requests_total ed etichette method=”POST” e handler=”/messages” può essere scritta così:
api_http_requests_total{method="POST", handler="/messages"}Il nome della metrica specifica la caratteristica generale del sistema che si vuole misurare (per esempio api_http_request_total - il numero di richieste http ricevute dal una API). Può contenere caratteri ASCII e numerici, così come underscore e due punti, in pratica deve fare il match con la regex [a-zA-Z_:][a-zA-Z0-9_:]*.
Note: I due punti sono riservati per le user defined recording rules. Non dovrebbero essere utilizzati direttamente dagli exporter.
Le etichette (label) abilitano il multi-dimensional data model di Prometheus: ogni combinazione di label for la solita metrica identificano una particola istanziazione di quella metrica (per esempio tutte le richieste HTTP che utilizzano il method POST sul handler /messages. Il linguaggio di query permettere di filtrare ed aggregrare i dati basandosi su queste dimensioni. Cambiare un singolo valore di una label, compreso aggiungere o rimuovere una label creerà una nuova time series.
I nomi delle label possono contenere lettere ASCII, numeri ed underscore, devono cioè rispettare la regex [a-zA-Z_][a-zA-Z0-9_]*.
Le label che cominciano con _ sono riservate ad uso interno del Prometheus. I valori delle label possono contenere qualunque carattere Unicode.
[Prometheus] include un database locale su disco delle time series ed opzionalmente ha la possibilità di integrare un sistema remoto di storage dei dati.
Il database locale archivia i dati delle time series in un formato specifico su disco. I dati sono raggruppati in blocchi di due ore. Ogni blocco di due ore consiste in una directory contenente uno o più chunk file contenenti tutti i campionamenti delle time series per quella finestra di tempo, così come i file di metadata ed indice.
Il blocco relativo alle time series delle ultime due ore è mantenuto in memoria e non ancora persistito su disco ed è messo in sicurezza dai crash dell’applicazione tramite un write-ahead-log (WAL) che può essere ri-eseguito quando il Prometheus viene riavviato dopo un crash.
È da notare che una limitazione del local storage è che non è clusterizzato ne replicato. Quindi non è arbitrariamente scalabile o affidabile indipendentemente dal disco locale o dall’affidabilità del nodo prometheus e deve essere trattato piuttosto come una finestra temporale scorrevole dei dati più recenti.
Questo formato utilizzato per l’archiviazione dei dati prometheus è il [TSDB].
Prometheus supporto alcuni parametri che permettono di configurare lo storage locale, i più importanti sono:
—storage.tsdb.path: identifica dove il Prometheus scrive il proprio database. Il default è data/.
—storage.tsdb.retention.time: determina quando rimuovere i vecchi dati. Il default è 15d.
—storage.tsdb.retention: questo parametro è stato deprecato in favore di storage.tsdb.retention.time.
In media Prometheus utilizza solo 1-2 byte per campionamento grazie ad un meccanismo incrementale di salvataggio dei dati. Quindi per pianificare la capacità disco di un Prometheus server è possibile utilizzare la seguente formula approssimativa:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
Per ottimizzare il rate dei sample archiviati per secondo è possibile ridurre il numero delle time series di cui fare scrape (meno target o meno serie per target) oppure incrementare lo scrape interval.
Se lo storage locale diventa corrotto per qualsiasi motivo la cosa migliore da fare è spegnere il Prometheus e rimuovere l’intera directory di storage. Filesystem non compatibili POSIX non sono supportati come local storage di Prometheus e ne è sconsigliato l’utilizzo perché possono corrompersi senza possibilità di recupero. Per esempio NFS è solo “potenzialmente” POSIX, molte implementazioni non lo sono.
Prometheus fornisce un query language chiamato PromQL (Prometheus Query Language) che per permette di selezionare ed aggregare i dati delle time serie in real time. I risultati di una espressione PromQL possono essere utilizzati per visualizzare un grafico, visualizzare i dati in forma tabellare nel Expression Browser del Prometheus o per essere consumati da un sistema esterno tramite l’APIHTTP.
Nel seguoto sono riportati alcuni esempi di query PromQL che ne esemplificano l’utilizzo.
Restituire tutte le time serie con la metriche con nome http_requests_total:
http_requests_total
Restituire tutte le metriche http_requests_total che hanno le etichette job ed handler come specificato:
http_requests_total{job="apiserver", handler="/api/comments"}Restituire l’intero intervello di tempo (in questo caso 5 minuti) della serie temporale, rendendolo un range vector:
http_requests_total{job="apiserver", handler="/api/comments"}[5m]Da notare che il risultato di questa espressione non può essere graficato direttamente ma visualizzato in vista tabellare (“Console”) dell’Expresion browser.
Utilizzando le espressioni regolari è possibile selezionare le time serie il cui nome di un job corrisponde ad un certo path, per esempio in questo caso tutti i job che finiscono con “server“:
http_requests_total{job=~".*server"}Tutte le espressioni regolari di Prometheus utilizzano la sintassi RE2.
Per selezionare tutti gli HTTP status codes eccetto i 4xx, è possibile utilizzare la seguente query:
http_requests_total{status!~"4.."}Restituire la frequenza per secondo di tutte le time serie con nome della metrica http_requests_total, misurate negli ultimi 5 minuti:
rate(http_requests_total[5m])
Assumendo che tutte le time serie http_requests_total abbiano la label job (che contiene il job name) e instance (che contiene l’instanza del job), noi potremo voler sommare la frequenza di tutte le istanze, così da ottenere in output un numero minore di time series ma preservando la dimensione job:
sum(rate(http_requests_total[5m])) by (job)
Se si hanno due differenti metriche con la stesso insieme di label è possibile applicargli un operatore binario e gli elementi di entrambi i lati con lo stesso nome delle label verranno accoppiati (ne verrà applicato l’operatore) e propogato il risultato nell’output. Nell’esempio successivo l’espressione restituisce in MiB la memoria non utilizzata per ogni istanza:
(instance_memory_limit_bytes - instance_memory_usage_bytes) / 1024 / 1024
La stessa espressione ma sommata per applicazione può essere scritta come segue:
sum( instance_memory_limit_bytes - instance_memory_usage_bytes ) by (app, proc) / 1024 / 1024
Segui la seconda parte del tutorial per imparare ad avviare ed utilizzare Prometheus.
[Prometheus] https://prometheus.io/
[SoundCloud] https://soundcloud.com/
[CCNF] https://www.cncf.io/
[Kubernetes] https://kubernetes.io/
Business Software Solutions